The Ultimate Handbook for LLM Quantization

LLMs on CPU? Yes, you heard it right. From handling conversations to creating its own images, AI has come a long way since its beginnings. But it came with a bottleneck. As the models expanded, so did their computational demands. AI began to rely heavily on computational power. To meet these demands, we turned to GPUs, and the rest is history.
Many devices don't possess powerful GPUs and so miss out on AI capabilities. It was necessary to scale down the size and power of these models to run an AI model on devices with limited computational power like a mobile phone or a computer with CPU only. Early efforts include techniques like pruning and distillation. However, these approaches were not viable when it came to LLMs, which typically have large-scale architectures.
The recent AI revolution with LLMs was more or less based on cloud servers for training, deployment, and inference. However, major players are now extending LLM capabilities to edge devices. Microsoft's copilot+PCs is a great example and something to wait for. As we move toward edge deployment, optimizing LLM size becomes crucial without compromising performance or quality. One effective method to achieve this optimization is through quantization.
In this article, we will deeply explore quantization and some state-of-the-art quantization methods. We will also see how to use them.
Table of Contents
· Quantization: What & Why ∘ Linear/Scale Quantization ∘ Affine Quantization ∘ Post-Training Quantization (PTQ) ∘ Quantization-Aware Training ∘ Why Quantize? · Latest SOTA Quantization Methods ∘ LLM.int8() (Aug 2022) ∘ GPTQ (Oct 2022) ∘ QLoRA (May 2023) ∘ AWQ (Jun 2023) ∘ Quip# (Jul 2023) ∘ GGUF (Aug 2023) ∘ HQQ (Nov 2023) ∘ AQLM (Feb 2024) · Conclusion · References
Quantization: What & Why ❓
The weights of a neural network can be represented in various datatypes based on the precision requirements and computational resources available. Quantization is a procedure that maps the range of high precision weight values like FP32, which is determined by the [min, max] of the datatype, into lower precision values such as FP16 or even INT8 (8-bit Integer) datatypes.

Consider your 400M parameter LLM. Usually, weights are stored in FP32(32-bit). The memory footprint of this model can be calculated as:
4×10⁸ params x 4 bytes = 1.6 Gigabytes
Quantizing the above model can reduce the size significantly. Consider a conversion from FP32 to INT8. The quantized model's memory footprint can be calculated as:
4×10⁸ params x 1 byte = 0.4 Gigabytes
That is 1/4th of the original size! **** This helps the model occupy less memory and also enhances inference speed although it may compromise the accuracy a bit. Also, some of these lightweight models can be easily handled by a CPU.

The range mapping of weights during quantization is typically accomplished using two methods.
Linear/Scale Quantization
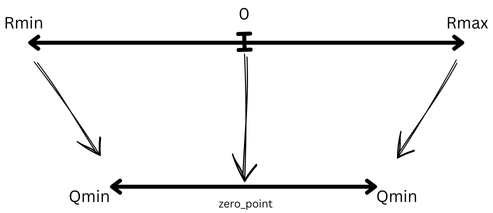
Here quantization is similar to scaling in the specified range. Rmin is mapped to Qmin and Rmax to Qmax accordingly. ** The 0 in the actual range is mapped to a corresponding zero_poin**t in the quantized range.

Affine Quantization
This method allows representing more asymmetric ranges. The parameters here are:

For INT8 datatype, the equation can be

After this transformation is applied, some data will be out of range. To bring them in range, an additional clip operation is used.

When it comes to quantizing Large Language Models (LLMs), there are two primary types of quantization techniques:
Post-Training Quantization (PTQ)
As the name suggests, the Llm is quantized after the training phase. The weights are converted from a higher precision to a lower precision data type. It can be applied to both weights and activations. Although speed, memory, and power usage are highly optimized, there is an accuracy trade-off. During quantization, rounding or truncation occurs, introducing quantization error. This error affects the model's ability to represent fine-grained differences between weights.
Quantization-Aware Training
This technique was developed to mitigate the potential loss of model accuracy in the case of PTQ. In contrast to PTQ, the quantization process is integrated with the training itself, hence making the process "Quantization Aware".
In QAT, the model architecture is initially modified to maintain both full-precision and quantized versions of elements, which includes weights and activations, thereby creating a dual storage system. During the forward pass of the training process, a simulated or "fake" quantization is introduced to the model, allowing it to experience the effects of quantization while still preserving the precision when calculating gradients, thereby enhancing the model's robustness to quantization.

