How to mask PII data with FPE using Azure Synapse

1. Introduction
A lot of enterprises require representative data in their test environments. Typically, this data is copied from production to test environments. However, Personally Identifiable Information (PII) data is often part of production environments and shall first be masked. Azure Synapse can be leveraged to mask data using format preserved encryption and then copy data to test environments. See also architecture below.
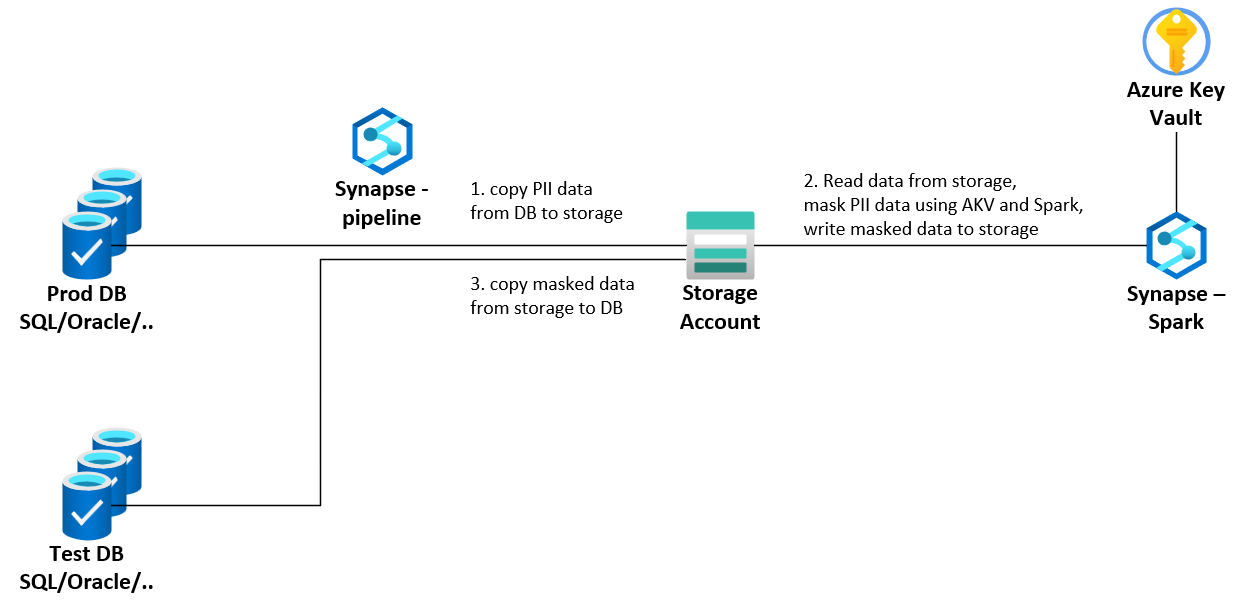
In this blog and repo[azure-synapse_mask-data_format-preserved-Encryption](https://github.com/rebremer/azure-synapse_mask-data_format-preserved-encryption), it is discussed how a scalable and secure masking solution can be created in Synapse. In the next chapter, the properties of the project are discussed. Then the project is deployed in chapter 3, tested in chapter 4 and a conclusion in chapter 5.
2. Properties of PII masking application in Synapse
Properties of the PII masking appication in Synapse are as follows:
-
Extendable masking functionality: Extending on open source Python libraries like ff3, FPE can be achieved for IDs, names, phone numbers and emails. Examples of encryption are 06–23112312 => 48–78322271, Kožušček123a => Sqxbblkd659p, [email protected] => [email protected]
- Security: Synapse Analytics workspace that used has the following security in place: Private endpoints to connect to Storage Account, Azure SQL (public access can be disabled) and 100 of other data sources (including on-premises); Managed Identity to authenticate to Storage account, Azure SQL and Azure Key Vault in which the secrets are stored that are used by ff3 for encryption; RBAC authorization to grant access to Azure Storage, Azure SQL and Azure Key Vault and Synapse data exfiltration protection to prevent that data leaves the tenant by a malicious insider
- Performance: Scalable solution in which Spark used. Solution can be scaled up by using more vcores, scaling out by using more executors (VMs) and/or using more Spark pools. In a basic test, 250MB of data with 6 columns was encrypted and written to storage in 1m45 using a Medium sized Spark pool with 2 executors (VMs) and 8 vcores (threads) per executor (16 vcores/threads in total)
- Orchestration: Synapse pipelines can orchestrate the process end to end. That is, data can be fetched from cloud/on-premises databases using over 100 different connectors, staged to Azure Storage, masked and then sent back to lower environment for testing.
In the architecture below, the security properties are defined.
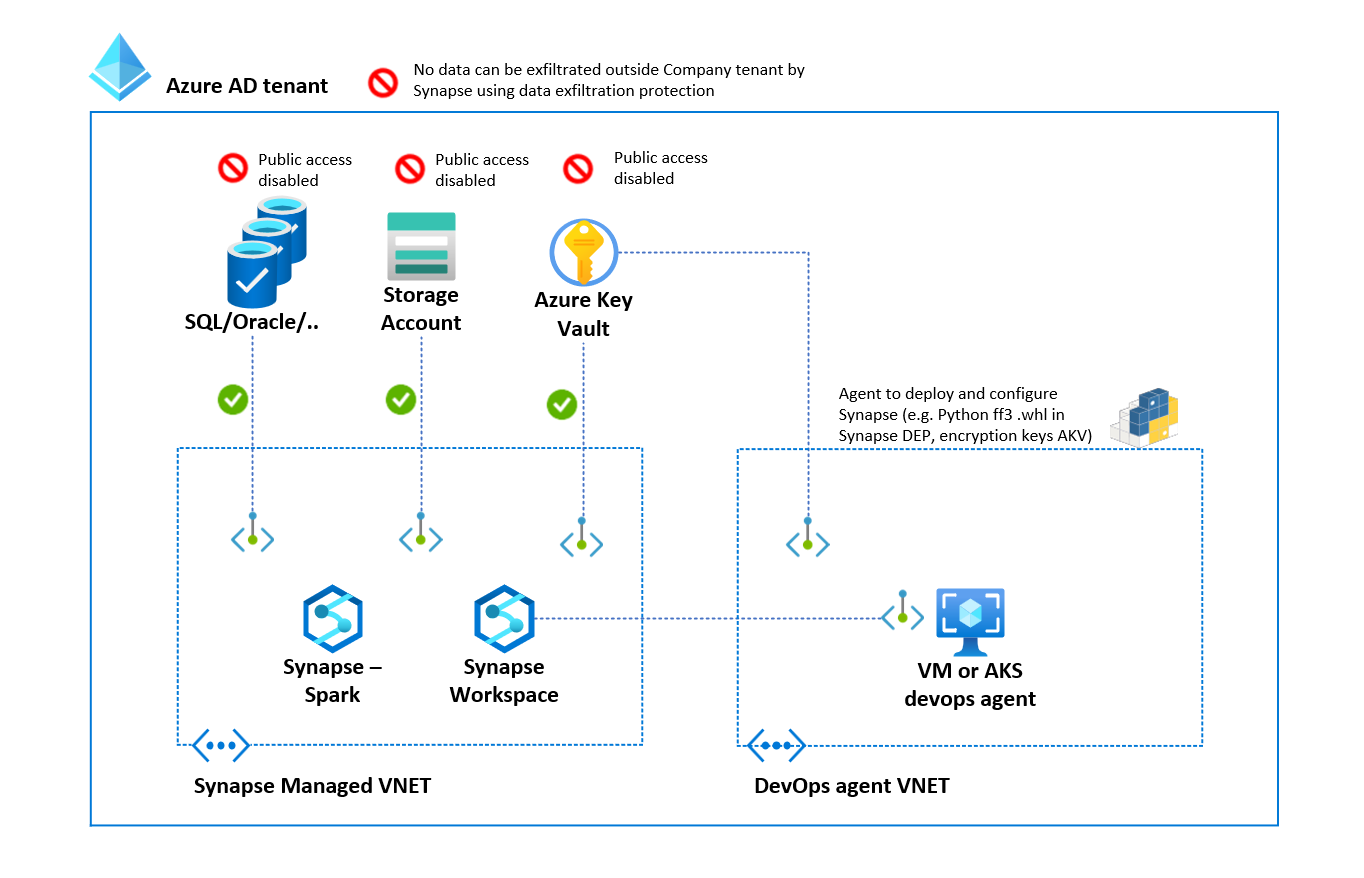
In the next chapter, the masking application will be deployed and configured including test data.
3. Deploy PII masking application in Synapse
In this chapter, the project comes to live and will be deployed in Azure. The following steps are executed:
- 3.1 Prerequisites
- 3.2 Deploy resources
- 3.3 Configure resources
3.1 Prerequisites
The following resources are required in this tutorial:
- Azure Account
- Azure CLI (recommended)
Finally, clone the git repo below to your local computer. In case you don't have git installed, you can just download a zip file from the web page.
3.2 Deploy resources
The following resources need to be deployed:
- 3.2.1 Azure Synapse Analytics workspace: Deploy Synapse with data exfiltration protection enabled. Make sure that a primary storage account is created. Make also sure that Synapse is deployed with 1) Managed VNET enabled, 2) has a private endpoint to the storage account and 3) allow outbound traffic only to approved targets, see also screenshot below:

- 3.2.2 Azure Key vault: This Key Vault will be used to store the secrets that are used to create the HMACs in
[Synapse/mask_data_fpe_prefixcipher.ipynb](https://github.com/rebremer/azure-synapse_mask-data_format-preserved-encryption/blob/main/Synapse/mask_data_fpe_prefixcipher.ipynb)and encryption in[Synapse/mask_data_fpe_ff3.ipynb](https://github.com/rebremer/azure-synapse_mask-data_format-preserved-encryption/blob/main/Synapse/mask_data_fpe_ff3.ipynb)
3.3. Configure resources
The following resources need to be configured
- 3.3.1 Storage Account – File Systems : In the storage account, create a new Filesystem called
bronzeandgold. Then upload csv file in[DataSalesLT.Customer.txt](https://github.com/rebremer/azure-synapse_mask-data_format-preserved-encryption/blob/main/Data/SalesLT.Customer.txt). In case you want to do a larger dataset, see this set of 250MB and 1M records - 3.3.2 Azure Key Vault – Secrets: Create a secret called
fpekeyandfpetweak. Make sure that hexadecimal values are added for both secrets. In case Azure Key vault was deployed with public access enabled (in order to be able to create secrets via Azure Portal), it is now not needed anymore and public access can be disabled (since private link connection will be created between Synapse and Azure Key vault in 3.3.4) - 3.3.3 Azure Key vault – access control: Make sure that in the access policies of the Azure Key Vault the Synapse Managed Identity had get access to secret, see also image below.

- 3.3.4 Azure Synapse Analytics – Private link to Azure Key Vault: Create a private endpoint from the Azure Synapse Workspace managed VNET and your key vault. The request is initiated from Synapse and needs to be approved in the AKV networking. See also screenshot below in which private endpoint is approved, see also image below

- 3.3.5 Azure Synapse Analytics – Linked Service link to Azure Key Vault: Create a linked service from the Azure Synapse Workspace and your key vault, see also image below

- 3.3.6 Azure Synapse Analytics – Spark Cluster: Create a Spark cluster that is Medium size, has 3 to 10 nodes and can be scaled to 2 to 3 executors, see also image below.

- 3.3.7 Azure Synapse Analytics – Library upload: Notebook
Synapse/mask_data_fpe_[ff3](https://github.com/mysto/python-fpe).ipynbuses ff3 to encryption. Since Azure Synapse Analytics is created with data exfiltration protection enabled, it cannot be installed using by fetching from pypi.org, since that requires outbound connectivity outside the Azure AD tenant. Download the pycryptodome wheel [[here](https://files.pythonhosted.org/packages/be/ea/90e14e807da5a39e5b16789acacd48d63ca3e4f23dfa964a840eeadebb13/Unidecode-1.3.6-py3-none-any.whl)](https://files.pythonhosted.org/packages/3a/c1/3550f1b97d6eedb2117521a149f379bb0d92cbb02e242110bb174f12c9a2/ff3-1.0.1-py3-none-any.whl) , ff3 wheel here and Unidecode library here (Unidecode library is leveraged to convert unicode to ascii first to prevent that extensive alphabets shall be used in ff3 to encrypt data). Then upload the wheels to Workspace to make them trusted and finally attach it to the Spark cluster, see image below.

- 3.3.8 Azure Synapse Analytics – Notebooks upload: Upload the notebooks
[Synapse/mask_data_fpe_prefixcipher.ipynb](https://github.com/rebremer/azure-synapse_mask-data_format-preserved-encryption/blob/main/Synapse/mask_data_fpe_prefixcipher.ipynb)and[Synapse/mask_data_fpe_ff3.ipynb](https://github.com/rebremer/azure-synapse_mask-data_format-preserved-encryption/blob/main/Synapse/mask_data_fpe_ff3.ipynb)to your Azure Synapse Analytics Workspace. Make sure that in the notebooks, the value of the storage account, filesystem, key vault name and keyvault linked services are substituted. - 3.3.9 Azure Synapse Analytics – Notebooks – Spark session: Open Spark session of notebook
Synapse/mask_data_fpe_prefixcipher.ipynb, make sure you choose more than 2 executor and run it using a Managed Identity, see also screenshot below.

4. Test solution
After all resources are deployed and configured, notebook can be run. Notebook Synapse/mask_data_fpe_prefixcipher.ipynb contains functionality to mask numeric values, alpanumeric values, phone numbers and email addresses, see functionality below.
000001 => 359228
Bremer => 6paCYa
Bremer & Sons!, LTD. => OsH0*VlF(dsIGHXkZ4dK
06-23112312 => 48-78322271
[email protected] => [email protected]
Kožušček123a => Sqxbblkd659pIn case the 1M dataset is used and 6 columns are encrypted, processing takes around 2 minutes. This can easily be scaled by using 1) scaling up by using more vcores (from medium to large), scaling out by using more executors or just create a 2nd Spark pool. See also screenshot below.
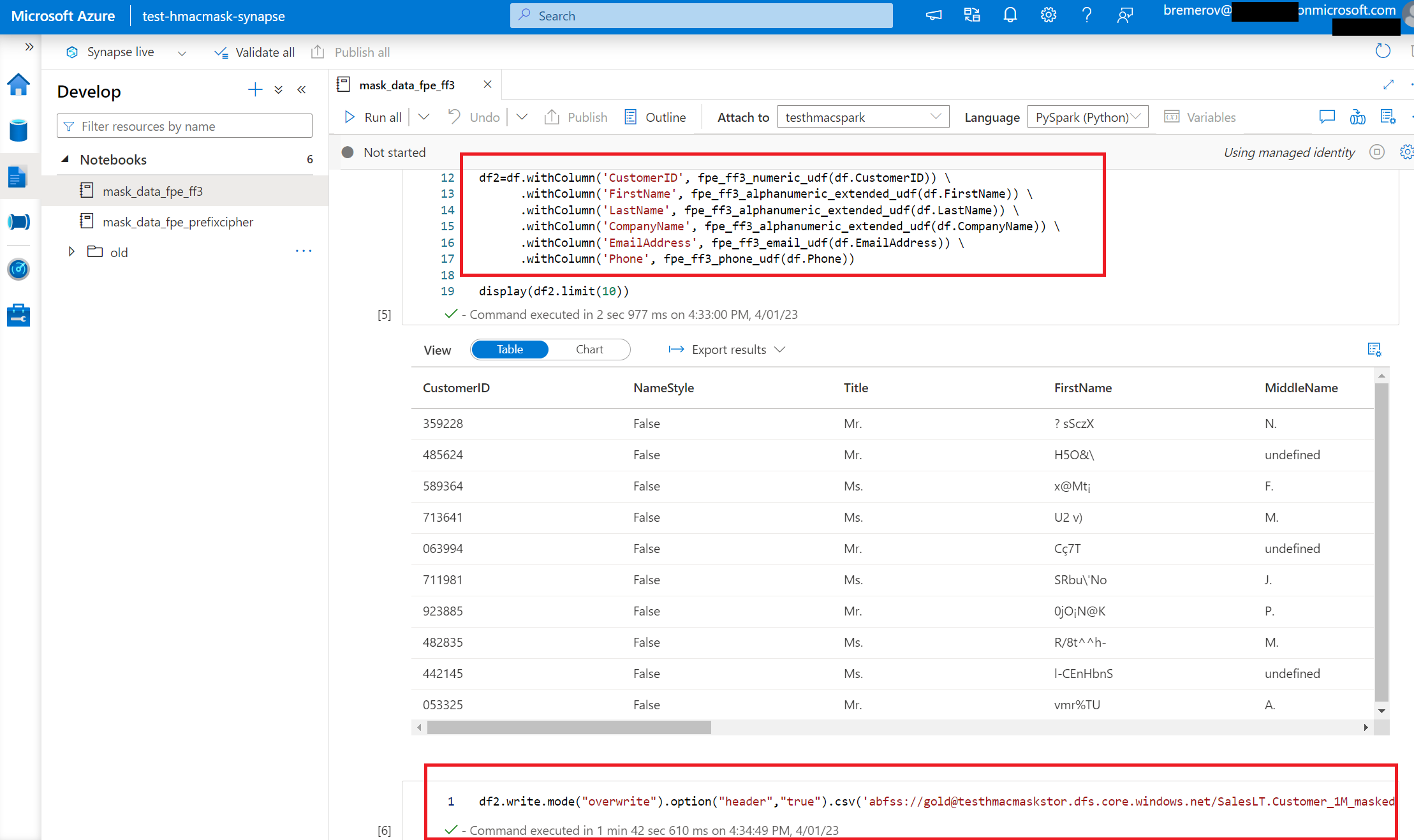
In Synapse, notebooks can be easily embedded in pipelines. These pipelines can be used to orchestrate the activities by first uploading the data from production source to storage, run notebook to mask data and then copy masked data to test targed. An example pipeline can be found in [Synapse/synapse_pipeline.json](https://github.com/rebremer/azure-synapse_mask-data_format-preserved-encryption/blob/main/Synapse/synapse_pipeline.json)
5. Conclusion
A lot of enterprises need to have representative sample data in test environment. Typically, this data is copied from a production environment to a test environment. In this blog and git repo[-synapse_mask-data_format-preserved-encryption](https://github.com/rebremer/azure-synapse_mask-data_format-preserved-encryption), a scalable and secure masking solution is discussed that leverages the power of Spark, Python and open source library ff3, see also architecture below.
